Introduction to B+ Tree [B+树简介]
B+ Tree是B Tree的一个升级,但是它比B Tree更适合实际应用中操作系统的文件索引和数据库索引(目前现代关系型数据库最广泛的支持索引结构就是B+ Tree)。因为B+ Tree的磁盘读写代价更低,查询效率更加稳定。一个数据库一般支持多种类型索引,而且一种索引也会建立在不同的key上。
先介绍一下B+ Tree的特点。
-
所有关键字都出现在叶子结点的链表中[稠密索引],且链表中的关键字恰好是有序的。
-
不可能在非叶子结点命中。
-
非叶子结点相当于是叶子结点的索引[稀疏索引],叶子结点相当于是存储[关键字]数据的数据层。
-
更适合文件索引系统。
Fig. 1是一个B Tree的例子,Fig.2是一个B+ Tree的例子。从这两个图的对比可以发现,二者的区别是:
B+树和m阶的B树的不同点在于:###
-
非叶子结点的子树指针与关键字个数相同,比如下两图中,Fig 1根节点中有三个key四个子树指针用于下级索引,但是Fig 2只有三个子树指针,与key数量相同,其原因在于第二个不同点,
-
非叶子结点的子树指针P[i],指向关键字值属于[K[i], K[i+1])的子树,而B Tree是(K[i], K[i+1]), B+ Tree每层索引都有K[i], B Tree每层索引都不包括K[i]和K[i+1]。
-
为所有叶子结点增加一个链指针。也就说所有叶子节点都是相连的。
-
所有关键字都在叶子结点出现[B+ Tree每个节点只包括Key,而B Tree每个节点包括Key-Value]。所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大[或最小]关键字。 而B树的非终节点也包含需要查找的有效信息
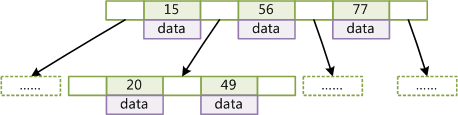
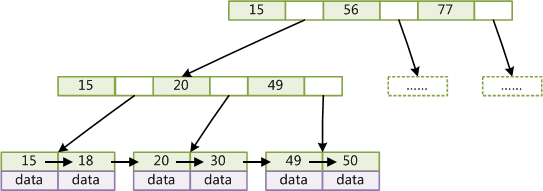
Note: 在实际使用中每个非叶子节点包含的key的数量都是非常巨大的,以保证B+ tree的高度不会太高。并且一般情况下,key的数量是固定的,如果想要修改就要重建一棵新的B+tree
B+ Tree的优势
说B+ Tree比B Tree更适合实际应用中操作系统的文件索引和数据库索引。网上给出的理由有两点,因为目前没有实际经验,所以只能先借鉴一下了(来源:http://stackoverflow.com/questions/870218/differences-between-b-trees-and-b-trees)
Because B+ trees don’t have data associated with interior nodes, more keys can fit on a page of memory. Therefore, it will require fewer cache misses in order to access data that is on a leaf node. 因为B+ Tree的每个节点不包括数据只有key,所以内存中可以容纳更多的key,需要的更少的cache。
The leaf nodes of B+ trees are linked, so doing a full scan of all objects in a tree requires just one linear pass through all the leaf nodes. A B tree, on the other hand, would require a traversal of every level in the tree. This full-tree traversal will likely involve more cache misses than the linear traversal of B+ leaves. B+ Tree的所有叶子节点都是相连的(因为每个叶子节点都有一个链指针),所以一次对所有数据的全遍历只需要一个线性遍历。但是B Tree要进行层层遍历,每次遍历都需要占用cache,所以这也是B+ Tree更适合的原因。