Parallel Database Architecture [并行数据库架构]
并行数据库[Parallel Database]是为了应对更高的数据吞吐要求而产生的数据库。它主要有三种架构模式:Shared Memory, Shared Disk,Shared Nothing。每种架构各有侧重,因为良好的scalability,Shared Nothing是目前主流的设计思路,Shared Disk在某些应用场景下也具有很大的优势,Shared Memory已经几乎没有用武之地了。Shared Memory, Shared Disk和Shared Nothing的架构实例如下图所示,
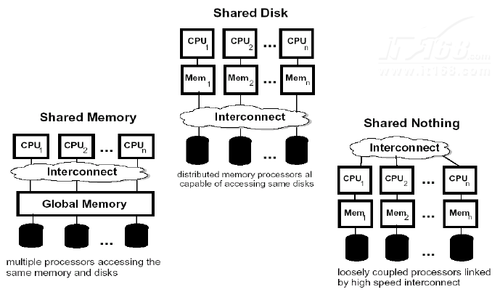
Shared Memory
Shared Memory指的是多个CPU共享一个Memory。此种架构可以提供非常高效的数据交换性能,不同的进程(CPU)因为共享一块内存,可以直接访问需要的数据而不用产生多余的数据备份。同时这样的设计也使得很多在常规数据库已经有的技术可以直接使用在Shared Memory的架构上,比如2PL[2 Phase Lock]可以直接应用不需要任何修改。但是缺点也是非常明显的,首先Share Memory本身就决定了Scalability不会太好,过多的Node[CPU/Machine]会产生竞争,Memory的总线[Bus]也会成为瓶颈。其次,fault-tolerance[容错性能]不好,如果memory crash或者出现错误那么整个并行数据库就会出现问题甚至也crash。
Shared Disk
Shared Disk指的是多个Node[CPU/Machine]共享一个Disk,但各自拥有自己的Memory。这种架构首先提高了Shared Memory架构的fault-tolerance能力,因为每个node都有自己的memory,即便一个甚至几个出现问题,整个平行数据库可能还是可以继续运行下去,同时,Scalability也得到了提升。但是因为共享一个disk,scalability的瓶颈就从memory变成了disk,多个节点在disk的竞争或者并发操作都会降低整个并行数据库系统的性能。这种架构多出现在business system中,因为这样的系统不会有太多的服务器,CPU不太多的情况下,竞争产生的overhead就不会太大。那么Shared Disk通讯代价小的优势就可以体现出来。
Shared Nothing
这种架构广泛出现于集群服务器的设计中,每个CPU拥有自己的memory和disk,彼此之间通过网络进行通讯和数据传输。其好处是明显的,Shared Disk和Shared Memory的架构随着CPU数量的提升会出现竞争,但是Shared Nothing并不会出现这样的情况。
As Google has demonstrated, a pure SN system can scale almost infinitely simply by adding nodes in the form of inexpensive computers, since there is no single bottleneck to slow the system down. Google calls this sharding.
如果partition机制比较好的话,SN架构可以带来非常好的throughput。同时另一个不能忽略的优势是这种架构的搭建成本相对于前两种比较低,上面的引用也说明了,Shared Nothing可以架构在很多台廉价PC之上。
Shared Nothing的缺点在于,相比较与前面两种模式,多个node之间的通讯开销就会变得很大。协调这些node也会带来很多overhead。同时对于数据库的一致性也有更多的挑战,如果在平行数据库Shared Nothing模式下,data被partition到每个node的disk,那么所有数据就只有一份,如果数据不在本地而该node又想访问的化,只好去对应的disk拿(当然,更好地做法是,把每一个数据都partition到每个disk,比如把table的平均切分到每个disk,然后再merge结果这样就保证了每个节点都可以进行操作,这其实就是mapreduce的做法,也难怪在mapreduce刚出的时候很多DB领域的大佬对它嗤之以鼻)。如果数据在多个节点同时拥有备份,那么就要额外的同步机制[Sync]来确保数据一致性。
Parallel Database vs Distributed Database
并行数据库的Shared Nothing模式和分布式数据库[Distributed Database]其实有点像。他们的主要区别在于三点:
-
并行数据库Shared Nothing模式虽然是多个机器构建的集群,但是一般在地理位置上还是一致的,都是把很多机器放在一个机房中,彼此适用高速光纤或者数据线相连,其通讯可以认为正常情况下是快速而且稳定的。但是分布式数据库很多情况下,在地理位置上是分开的,可能一个机器在美国另一个却在中国,彼此之间的通讯可能就是靠一般的网路来完成,稳定性也一般。
-
管理方式也不同,并行数据库是因为单一数据库系统的性能不能满足需求才这设计出多个硬件联合的架构来提升数据容量或者处理效率,但是从应用角度看整个数据库一般还是看成一个整体,统一管理。分布式数据库,因为距离可能较远,在显示环境下可能由不同的人员或机构维护,所以可能整个分布式数据库的每个节点是单独管理的。
-
并行数据库基本上是用相同的机器构建集群[homogeneous cluster],以便达到更好地balance。而分布式数据库更多时候需要将很多完全不同的机器连在一次形成分布式数据库[heterogeneous cluster]。其中区别不言自明。