Introduction to GPU and CUDA [GPU和CUDA简介]
因为现在的项目依赖于GPU,所以需要对GPU有深入的了解,本文总结了一下自己对GPU架构的理解
1. Overview [概述]
如果要跳过所有细节,只想简单的理解GPU特性或者GPU和CPU的区别那么,那么可以简单的理解成,CPU就像是一个精英工作组,组内成员不多,但是个个都是独当一面的高手,所以他们凑在一次无论是复杂的科研任务还是小学生算术题,都可以解决,但是因为人员不多,一旦遇上大量的任务[哪怕每个任务都是计算10以内加减法],那么CPU做起来就会比较慢。相对的,GPU就像是一个大型工厂,拥有众多普通工人,每个工人只能处理简单任务,但是对于大量的简单任务,这个大型工厂就可以快速解决。基本上如果单纯考虑计算能力,GPU的速度是CPU的几十倍。
2. Basic Concept [基本概念]
首先介绍一些GPU相关的概念。
GPU Driver: 也称显卡驱动,目前主流的显卡是NVIDIA和AMD两家,所以基本上驱动也是对应这两个品牌。所谓驱动就是供操作系统调用的API库来正常使用GPU。
GPGPU: General-purpose Computing on Graphics Processing Units, 提出通用目的图形处理器主要是为了取代CPU。目前大部分的计算机都采用CPU+GPU的异构架构,也就是由CPU进行任务调度,GPU执行计算任务。
CUDA & OpenCL: CUDA [Compute Unified Device Architecture]是由NVIDIA提出的统一计算架构,也是NVIDIA对于GPGPU的正式名称。通过CUDA,用户可以用CUDA-C语言编写程序,编写的程序可以直接被GPU执行[包括交换,同步,共享数据],这样从一定程度上跳过了CPU,从而达到实现GPGPU的目的。CUDA也是一个可供用户调用的API库。但是CUDA只能用于NVIDIA的GPU,而AMD使用的是OpenCL[Open Computing Language]作为替代方案,两个功能相似,但CUDA闭源,OpenCL开源。
SP [CUDA Core]: 最基本的处理单元,Streaming Processor,也称为CUDA core。最后具体的指令和任务都是在SP上处理的。所谓GPU并行计算,也就是很多个SP同时做处理。
SM: 多个CUDA Core加上其他的一些资源组成一个Streaming Multiprocessor,也叫GPU大核。这里说的其他资源包括:warp scheduler,register,shared memory等。SM可以看做GPU的心脏[对比CPU核心],register和shared memory是SM的稀缺资源,CUDA将这些资源分配给所有驻留在SM中的threads。因此,这些有限的资源就使每个SM中active warps有非常严格的限制,也就限制了并行能力,换句话说register和shared memory越大,其GPU并行能力越强。一般来说,不同的GPU拥有多个SM,每个SM有多个CUDA Core。比如一个GPU可能有32个SM,然后每个SM有48个CUDA Core,这个GPU就会有上千个CUDA Core,目前主流GPU至少拥有2000个CUDA Core。
3. GPU Architecture [GPU 架构]
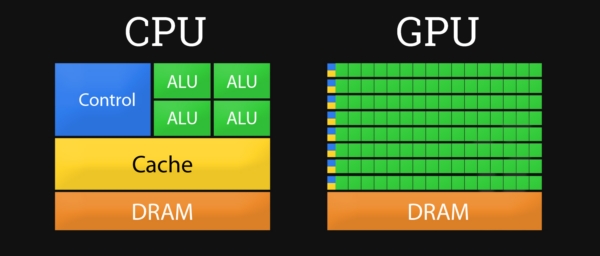
如下图所示的CPU和GPU架构图[当然这个只是high-level的,具体实现各厂商也有所区别,多年后可能这个架构也会变化],CPU拥有强大的控制单元[Control Unit],逻辑运算单元[ALU],和更大的缓存[Cache],所以CPU可以处理复杂的逻辑运算,并且储存更多的中间结果以备后续计算使用。相对CPU,GPU的控制单元,运算单元和缓存都相对弱一些,但是运算单元的数量却更多,所以GPU的逻辑控制单元基本上只处理分发合并等简单逻辑,而GPU的计算单元则可以一次处理很多的简单任务。所以CPU可以用来调度计算机的各种任务,而GPU可以用来处理无数的小型计算来渲染图片或者训练神经网络模型。
4. CUDA
如前文所述,CUDA是NVIDIA提出的统一计算架构,也是NVIDIA对于GPGPU的正是名称,但是它本质是一个异构编程模型,需要CPU和GPU协同工作,其中host和device是两个重要概念,前者是CPU及其内存而device是GPU及其内存。所以CUDA编程既包括host程序也包括device程序,同时他们之间也要进行必要的通讯和数据通讯。
CUDA编程的大致流程是:
- 分配host内存,并进行数据初始化
- 分配device内存,并从host将数据拷贝到device上
- 调用CUDA的API再device上完成指定的运算
- 将device上的运算结果拷贝到host上
- 释放device和host上分配的内存
4.1 Execution Architecture[执行架构]
CUDA是一种典型的SIMT架构[Single Instruction, Multiple Threads 单指令多线程架构],SIMT和SIMD[Single Instruction, Multiple Data]类似,SIMT应该算是SIMD的升级版,更灵活,但效率略低,SIMT是NVIDIA提出的GPU新概念。二者都通过将同样的指令广播给多个执行单元来实现并行。一个主要的不同就是,SIMD要求所有的vector element在一个统一的同步组里同步的执行,而SIMT允许线程们在一个warp中独立的执行。
这里介绍以下CUDA程序执行和GPU硬件的对应关系。
- GPU中小的计算单元是CUDA Core,对应到CUDA程序中就是一个线程Thread。所以GPU CUDA Core<–>CUDA Thread
- GPU中多个CUDA Core就会组成一个SM,对应到CUDA程序中就是一个线程块Block。所以GPU SM<–>CUDA Block,一个Block在任何时间只会由一个SM调度,所以他们是一一对应的关系。但是一个SM可以同时拥有多个Block,不过多个Block需要序列执行。同一个Block中的Threads可以同步,也可以通过shared memory通信
- 多个SM就组成了整个GPU,对应到CUDA就是其开始时的Thread Grid。一个Grid包含多个Block。
- 最后还有一个Warp的概念,Warp包含32个Thread,其为GPU执行程序的调度单位[而不是Thread]。所以其实是Grip>Block>Warp>Thread。Thread虽然是最小的计算单元,但Warp是任务的最小调度单位。
4.2 Memory Architecture[内存架构]
GPU的内存架构和CPU类似也是多级模式,越大的内存访问速度越慢。首先,每个线程有自己的本地内存[local memory],这是访问速度最快的内存空间,但是只能是线程自己访问。然后,每个线程块Block内有共享内存[Shared Memory],此共享内存可以被线程块中的所有线程共享。最后,每个线程可以访问全局内存[Gloabl Memory],我们平时说的GPU内存就是说的全局内存。
本文部分内容来源互联网