Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective
Abstract: Machine learning sits at the core of many essential products and services at Facebook. This paper describes the hardware and software infrastructure that supports machine learning at global scale. Facebook’s machine learning workloads are extremely diverse: services require many different types of models in practice. This diversity has implications at all layers in the system stack. In addition, a sizable fraction of all data stored at Facebook flows through machine learning pipelines, presenting significant challenges in delivering data to high-performance distributed training flows. Computational requirements are also intense, leveraging both GPU and CPU platforms for training and abundant CPU capacity for real-time inference. Addressing these and other emerging challenges continues to require diverse efforts that span machine learning algorithms, software, and hardware design.
TL;DR
-
Machine learning is applied pervasively across nearly all services, and computer vision represents only a small fraction of the resource requirements.
-
Facebook relies upon an incredibly diverse set of machine learning approaches including, but not limited to, neural networks.
-
Tremendous amounts of data are funneled through Facebook machine learning pipelines, and this creates engineering and efficiency challenges far beyond the compute nodes.
-
Facebook currently relies heavily on CPUs for inference, and both CPUs and GPUs for training, but constantly prototypes and evaluates new hardware solutions from a performance-per-watt perspective.
-
The frequency, duration, and resources used by offline training for various workloads:
| Service | Resource | Training Frequency | Training Duration |
|---|---|---|---|
| News Feed | Dual-Socket CPUs | Daily | Many Hours |
| Facer | GPUs + Single-Socket CPUs | Every N Photos | Few Seconds |
| Lumos | GPUs | Multi-Monthly | Many Hours |
| Search | Vertical Dependent | Hourly | Few Hour |
| Language Translation | GPUs | Weekly | Day |
| Sigma | Dual-Socket CPUs | Sub-Daily | Few Hours |
| Speech Recognition | GPUs | Weekly | Many Hours |
Machine Learning Workloads at Facebook
A training phase at Facebook generally performed offline. Training the models is done much less frequently than inference, it is generally on the order of days. Training also takes a relatively long time to complete, typically hours or days.
Machine learning algorithms used at Facebook include Logistic Regression (LR), Support Vector Machines (SVM), Gradient Boosted Decision Trees (GBDT), and Deep Neural Networks (DNN). But DNNs are the most expressive, potentially providing the most accuracy, but utilizing the most resources. Among all DNNs, there are three general classes in use: Multi-Layer Perceptrons (MLP), Convolutional Neural Networks (CNN), and Recurrent Neural Networks (RNN/LSTM). MLP networks are usually for ranking or recommendation, CNNs work for image processing), and RNN/LSTM networks are often for language processing.
Within Facebook, ONNX (Open Neural Network Exchange) is used as primary means of transferring research models from the PyTorch environment to high-performance production environment in Caffe2.
Resource Implications of Machine Learning
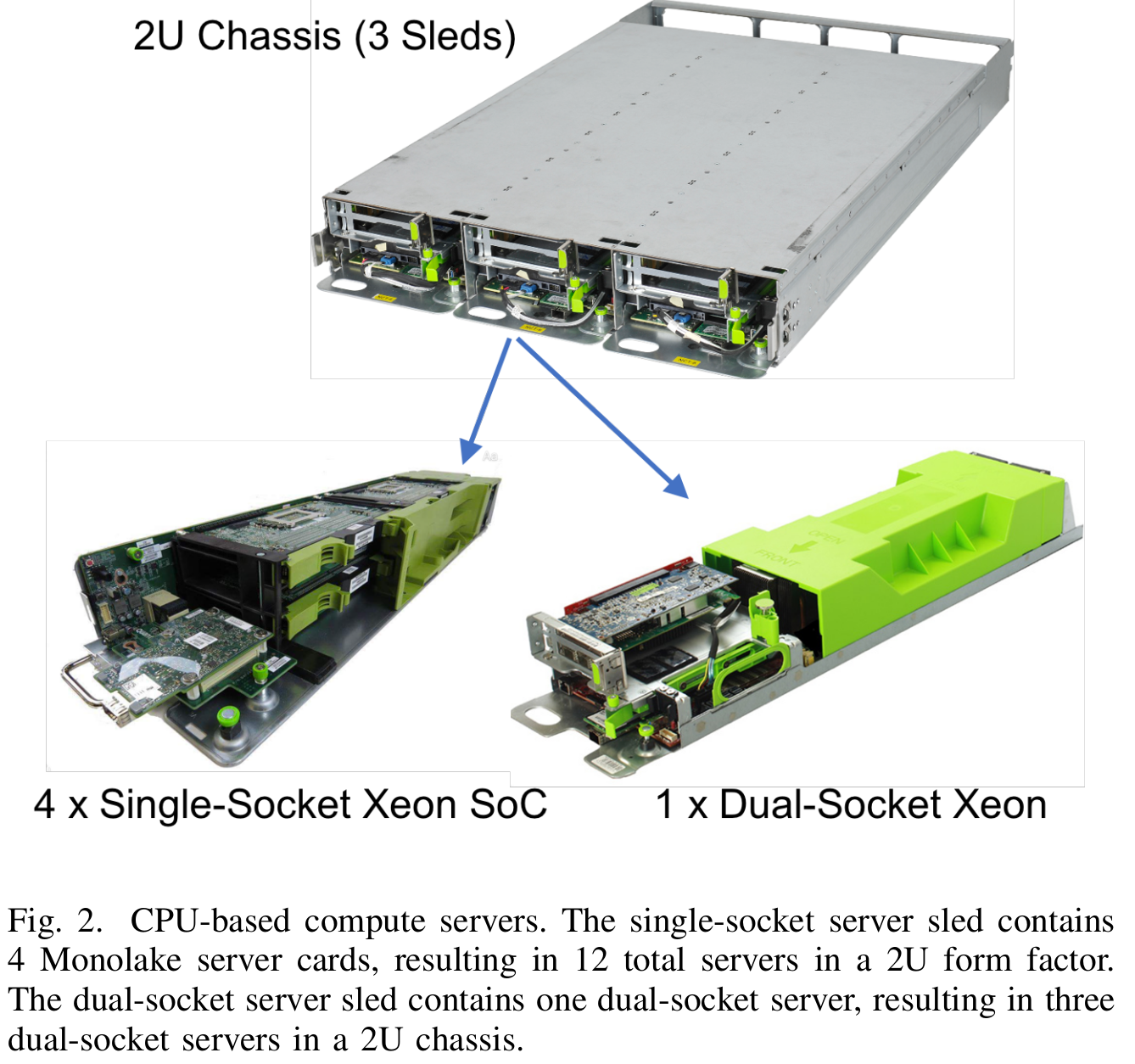
Facebook currently (2018-2019) supports roughly eight major compute and storage rack types that map to the same number of major services. For example, one rack type could be a 2U chassis that accommodates three compute sleds supporting two alternative server types. One sled option is a single socket CPU server (1xCPU) supported for the web tier, which is a throughput-oriented stateless workload, and therefore can be well served by a more power-efficient CPU with a relatively small amount of DRAM (32GB) and minimal on-board disk or flash storage. Another sled option is a larger dual socket CPU server with large amounts of DRAM that is used for compute- and memory-intensive services.
To accelerate the progress of training larger and deeper neural networks, Facebook also created Big Basin. The initial Big Basin design included eight NVIDIA Tesla P100 GPU accelerators connected using NVIDIA NVLink to form an eight-GPU hybrid cube mesh
The primary use case of GPU machines is offline training, rather than serving real-time data to users. This flows logically given that most GPU architectures are optimized for throughput over latency. Meanwhile, the training process does heavily leverage data from large production stores, therefore for performance and bandwidth reasons, the GPUs need to be in production near the data accessed. So the locality to the data source (many of which are regional) is becoming more important over time (this is usually true for global-level data center).
Data parallelism is employed to achieve better performance, which also make distributed training an active research area both at Facebook and in the general AI research community. Model parallelism training can be employed for training some exceptionally large models, where the model layers are grouped and distributed to optimize for throughput with activations pipelined between machines. But this increases end-to-end latency of the model, so the raw performance gain in step time is often associated with a degradation in step quality.
Machine Learning at Datacenter Scale
Facebook decouples the data workload from the training workload. These two workloads have very different characteristics. The data workload is very complex, ad-hoc, business dependent, and changing fast. The training workload on the other hand is usually regular (e.g. GEMM), stable (there are relatively few core operations), highly optimized, and much prefers a “clean” environment (e.g., exclusive cache usage and minimal thread contention).
To optimize for both, Facebook physically isolates the different workloads to different machines. The data processing machines, aka “readers”, read the data from storage, process and condense them, and then send to the training machines aka “trainers”. The trainers, on the other hand, solely focus on executing the training options rapidly and efficiently. Both readers and trainers can be distributed to provide great flexibility and scalability.
Due to variations in user activity due to diurnal load and peaks during special events (e.g. regional holidays), a large pool of servers are often idle at certain periods in time. A major ongoing effort explores opportunities to take advantage of these heterogeneous resources that can be allocated to various tasks in an elastic manner, especially for scaling distributed machine learning jobs to a large number of heterogeneous resources (e.g. different CPU and GPU platforms with differing RAM allocations).
The scheduler must first balance the load properly across heterogeneous hardware, so that hosts do not have to wait for each other for synchronization. The scheduler must also consider the network topology and synchronization cost when training spans multiple hosts. If not handled properly, the heavy intra- or inter-rack synchronization traffic could significantly deteriorate the training speed and quality. For example, in the 1xCPU design, the four 1xCPU hosts share a 50G NIC. If all four hosts attempt to synchronize their gradients with other hosts at the same time, the shared NIC will soon become the bottleneck, resulting in dropped packets and timeouts. Therefore, a co-design between network topology and scheduler is needed to efficiently utilize the spare servers during off-peak hours. In addition, such algorithms must also have the capability to provide check-pointing to stop and restart training as loads change.
Reference:
- Kim Hazelwood, Sarah Bird, David Brooks, Soumith Chintala, Utku Diril, Dmytro Dzhulgakov, Mohamed Fawzy et al. “Applied machine learning at facebook: A datacenter infrastructure perspective.” In IEEE International Symposium on High Performance Computer Architecture (HPCA), pp. 620-629. IEEE, 2018.