Revisit Join
Join[连接]是数据库查询最重要的操作,应该没有之一,主要用于连接两个以上的表并获得对应的结果。Join可以从类型和算法实现两个角度理解。
Join 类型
常见的Join类型有Inner Join, Left Join, Right Join, Full Join。下图简单明了的说明了四种Join类型的区别。
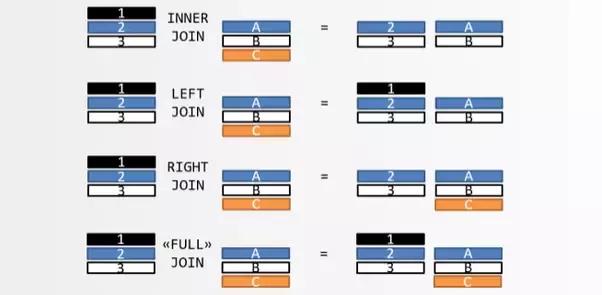
上图中,表 A 的记录是 123,表 B 的记录是 ABC,颜色表示匹配关系,需要注意的是返回结果中,如果另一张表没有匹配的记录,则用 null 填充。
从上图中也可以看出,这四种join又可以分成两大类: Inner Join和Outer Join,前者表示这类的join只会得到包含匹配的记录,而后者则还包含不匹配的记录,所以按照找个分类,只有Inner Join是Inner Join[这两个虽然同名但是两个维度],但是Left Join, Right Join, Full Join都是Outer Join。
Join类型一般可以体现在SQL语句中,也就是说用户可以在SQL语句中明确指定使用哪种Join,Join类型也会体现在Query Logical Plan中
Inner Join
一般情况下,如果在SQL语句中简单的使用Join关键字,那就是使用Inner Join。
select EmpName, City
from employees e
join address a
on e.empid=a.id
上面这个Inner Join的例子只返回两张表内匹配的记录,这里的匹配就是满足e.empid=a.id
Left Join
Left Join需要显式使用,下面的Left Join例子中,不但返回所有满条件的数据并且还有返回所有employees表中的没有匹配结果。
select EmpName, City
from employees e
left join address a
on e.empid=a.id
Right Join
Right Join需要显式使用,下面的Right Join例子中,不但返回所有满条件的数据并且还有返回所有address表中的没有匹配结果。
select EmpName, City
from employees e
right join address a
on e.empid=a.id
Full Join
Full Join需要显式使用,下面的Right Join例子中,不但返回所有满条件的数据并且还有返回address和employees表中的没有匹配结果。
select EmpName, City
from employees e
full join address a
on e.empid=a.id
Join 实现算法
相对于Join类型来说,Join的实现算法要硬核不少,这也是一个被学术圈和工业界研究了很多年的问题。一般情况下在Query Logical Plan中确定由Join的操作,那么接下来的问题就是如何实现这个操作,也就是在Physical Plan维度选择哪种join方式。
Join实现算法很多,但是最基础是三种[很多算法都是在他们的基础上发展出来的],Nested Loop Join[NLJ], Sort-Merge Join[SMJ],Hash Join[HJ]。
Nested Loop Join
使用NLJ连接两个表时,一个表作为outer table,另一个表作为inner table。具体哪个表是outer table,哪个是inner table,都无所谓,但是大多数情况下,会选择较小的表作为outer table来驱动整个NLJ,因为这样外表就只需要扫描一次
NLJ有三个常用方法,Simple Nested Loop Join, Index Nested Loop Join, Block Nested Loop Join,它们都是对应NLJ中的inner loop来说的
-
Simple Nested Loop Join: 就是简单的full scan作为inner table的表[个人感觉就是每次从位于disk的table中读取一行到内存],然后逐一进行条件比较,直到所有比较完成。
-
Index Nested Loop Join: 这个是较为常用的NLJ方法,具体就是对inner table的对应join字段建立index,这样就不用进行full scan而转而使用更高效的index来比较对应字段。
-
Block Nested Loop Join: 这是另一个常用的NLJ方法,并不是所有场景下建立index都是最高效的方法,这就可以引入join buffer的概念,就是每次读取一部分inner table[称为一个block]到内存,然后进行比较当前block的内容。这样可以避免频繁的I/O操作进而提高效率。
由于NLJ的性能不佳[包括其变种Index NLJ和Block NLJ],其很少在生产环境中真正使用。
Sort-Merge Join
Sort-Merge Join需要被连接的两个表处于被排序的状态,这就说明,如果两个表本身就已经是排序表那么使用这种join方法会非常高效,但是如果两个表处于为排序的状态,使用这种方法的代价就会非常高,因为排序通常都是十分消耗资源的。
SMJ的具体过程是,对两个表的需要的字段进行排序[或者默认两个表已经排好序了],然后在Merge进行比较。Merge过程中,两个表的比较是通过交替扫描比较的[因为两个表已经排好序了]。比如扫描表A=1,然后扫描表B=1,2,这时候会跳到表A=2,而不是从A=1再开始。
SMJ又可以分为internal SMJ和external SMJ,这取决于SMJ中的sort方法使用的是internal sorting[既所有排序都在内存中完成],还是external sorting[这种排序方法适用于内存不够大无法放入全部待排序数据,所以需要依靠外部存储来保存中间保存结果]。
Hash Join
相对于NLJ和SMJ来说,Hash Join只能做equal比较,而不能做类似大于,小于的比较。
Hash Join的实现分为build table和probe table两个步骤,前者会建立对两个表中较小的那个建立hash table[用小表是因为放入内存代价更小],probe table就是两个表中的大表。具体Hash Join的过程,首先依次读取小表的数据,对于每一行数据根据连接条件生成一个hash table中的一个元組,数据缓存在内存中。之后,依次扫描probe table,拿到每一行数据根据join condition生成hash key映射hash table中对应的元組,元組对应的行和probe table的这一行有着同样的hash key, 这时并不能确定这两行就是满足条件的数据,需要再次过一遍join condition和filter,满足条件的数据集返回需要的结果。
Hash Join可以通过Bloom Filter进一步优化。Bloom Filter一个高效的过滤器数据结构用来判断某一个key是否存在,其特点是虽然False Positive可能会发生[当Bloom Filter判断某一个Key存在时,这个Key可能其实不存在],但是False Negative永远不会发生[当Bloom Filter判断一个Key不存在时,就肯定不存在]。当在Hash Join的Probe阶段,可以先用Bloom Filter判断hash key是否存在,如果不存在就可以略过本次Probe。
如果是内存容量不够放下整个hash table情况,可以采用Grace Hash Join,其核心idea还是paritition,然后每次把一个partition放入内存进行hash join。
Reference
图片来源: https://www.ruanyifeng.com/blog/2019/01/table-join.html