DuckDB--Pipeline
本文重点记录一下DuckDB中最重要的概念之一Pipeline,以及具体在代码中如何实现的。
本质上来说,Pipeline机制把原本operator level的query execution变成了pipeline level,并且在每个pipeline中可以最小限度的进行并行计算从而提高效率。
Pipeline Design
DuckDB的Execution Model和Pipeline的概念,主要参考论文Morsel-Driven Parallelism: A NUMA-Aware Query Evaluation Framework for the Many-Core Age和Efficiently compiling efficient query plans for modern hardware。
DuckDB中,每个Query的Physical Plan会依据Pipeline Breaker被分割成一至多个Pipeline,并形成一个Pipeline DAG。Pipeline Breaker的定义是,那些需要处理所有子节点的数据后才能进行下一步计算输出结果的Physical Operator,比如hash join HT builder或者sort。每个Pipeline由Source,Operators,Sink构成,Source和Sink分别描述了这个pipeline的开始和结束结点,Operator是指处于Source和Sink的之间的一个或多个Physical Operators。
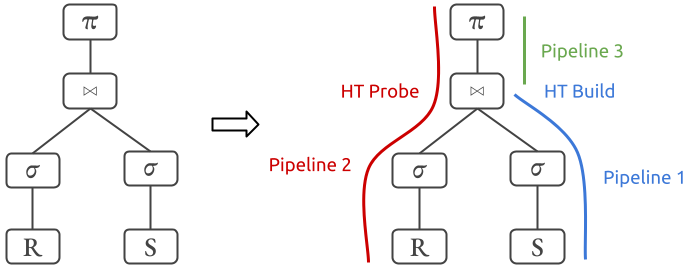
如上图所示,因为Hash Join(尤其是Build HT)是一个Pipeline Breaker,所以Physical Plan分割了Pipeline 1和Pipeline 2,同时DuckDB的Hash Join采用了Partitioned Hash Join,当数据量比较大的时候可以通过repartition将数据落盘避免OOM,所以为了实现这个多线程版本的partitioned hash join,还需要Pipeline 3。
-
Pipeline 1: 并发读取和计算所有build端的数据,并检查总数据量是否能全部放在内存中,如果不能就将build端的数据repartition,选出第一批能放在内存中的partition为它们构造hash table,剩下的数据存放在硬盘上。
-
Pipeline 2: 并发读取和计算所有probe端的数据,这时读上来的数据要么属于内存中的partition,要么属于硬盘上的partition,先把属于硬盘上的partition的数据落盘,用属于内存中的partition的数据去probe此时 build端的放在内存中的hash table,得到结果返回给上层。
-
Pipeline 3: 并发处理硬盘上的数据,挑选一批build端能放入内存的partition,构造hash table,然后 probe端去并发的 probe得到结果进行下一步计算。循环这样的处理过程直到所有硬盘上的partition都join完成。
Pipeline Implementation
DuckDB中,针对不同的Physical Operator有具体的实现[大部分在src/execution/operator中],他们要是实现定义在physical_operator.hpp中的接口,这些接口大致分为三个部分,Source,Sink和Pipeline construction。
Source主要接口包括:
// Source interface
virtual void GetData(ExecutionContext &context, DataChunk &chunk, GlobalSourceState &gstate, LocalSourceState &lstate) const;
virtual idx_t GetBatchIndex(ExecutionContext &context, DataChunk &chunk, GlobalSourceState &gstate, LocalSourceState &lstate) const;
virtual bool IsSource() const { return false; }
virtual bool ParallelSource() const { return false; }
Sinke主要接口包括:
// Sink interface
//! The sink method is called constantly with new input, as long as new input is available.
//! This method can be called in parallel, proper locking is needed when accessing data inside the GlobalSinkState.
virtual SinkResultType Sink(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate, DataChunk &input) const;
//! The combine is called when a single thread has completed execution of its part of the pipeline.
//! It is the final time that a specific LocalSinkState is accessible.
//! This method can be called in parallel while other Sink() or Combine() calls are active on the same GlobalSinkState.
virtual void Combine(ExecutionContext &context, GlobalSinkState &gstate, LocalSinkState &lstate) const;
//! The finalize is called when ALL threads are finished execution. It is called only once per pipeline.
//! It is entirely single threaded.
//! If Finalize returns SinkResultType::FINISHED, the sink is marked as finished
virtual SinkFinalizeType Finalize(Pipeline &pipeline, Event &event, ClientContext &context, GlobalSinkState &gstate) const;
例如,在physical_hash_join.cpp定义了Hash Join的各种接口,比如Sink。
SinkResultType PhysicalHashJoin::Sink(ExecutionContext &context, GlobalSinkState &gstate_p, LocalSinkState &lstate_p, DataChunk &input) const {
auto &gstate = (HashJoinGlobalSinkState &)gstate_p;
auto &lstate = (HashJoinLocalSinkState &)lstate_p;
// resolve the join keys for the right chunk
lstate.join_keys.Reset();
lstate.build_executor.Execute(input, lstate.join_keys);
// build the HT
auto &ht = *lstate.hash_table;
if (!right_projection_map.empty()) {
// there is a projection map: fill the build chunk with the projected columns
lstate.build_chunk.Reset();
lstate.build_chunk.SetCardinality(input);
for (idx_t i = 0; i < right_projection_map.size(); i++) {
lstate.build_chunk.data[i].Reference(input.data[right_projection_map[i]]);
}
ht.Build(lstate.join_keys, lstate.build_chunk);
} else if (!build_types.empty()) {
// there is not a projected map: place the entire right chunk in the HT
ht.Build(lstate.join_keys, input);
} else {
// there are only keys: place an empty chunk in the payload
lstate.build_chunk.SetCardinality(input.size());
ht.Build(lstate.join_keys, lstate.build_chunk);
}
// swizzle if we reach memory limit
auto approx_ptr_table_size = ht.Count() * 3 * sizeof(data_ptr_t);
if (can_go_external && ht.SizeInBytes() + approx_ptr_table_size >= gstate.sink_memory_per_thread) {
lstate.hash_table->SwizzleBlocks();
gstate.external = true;
}
return SinkResultType::NEED_MORE_INPUT;
}
Pipeline Build
另一个重要的接口是BuildPipelines。DuckDB中的Pipeline的构建来自每个Operator的BuildPipelines方法,通过实现这个方法,每个Operator会将自己加入到当前上下文的Pipeline ¤t中。另一个参数MetaPipeline &meta_pipeline主要用于维护拥有同一个Sink的多个Pipeline,所以大部分情况下meta_pipeline的长度还是为1的,主要在UNION ALL语句中pipelines数组的长度才不为1。meta_pipeline主要定义在meta_pipeline.hpp。
// Pipeline construction
virtual void BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline);
DuckDB中大部分Physical Operator的BuildPipelines函数都是继承并直接使用定义在physical_operator.cpp中的默认行为,而一些特殊的Operator,比如PhysicalRecursiveCTE、PhysicalUnion会重载这个虚函数。
void PhysicalOperator::BuildPipelines(Pipeline ¤t, MetaPipeline &meta_pipeline) {
op_state.reset();
auto &state = meta_pipeline.GetState();
if (IsSink()) {
// operator is a sink, build a pipeline
sink_state.reset();
D_ASSERT(children.size() == 1);
// single operator: the operator becomes the data source of the current pipeline
state.SetPipelineSource(current, this);
// we create a new pipeline starting from the child
auto child_meta_pipeline = meta_pipeline.CreateChildMetaPipeline(current, this);
child_meta_pipeline->Build(children[0].get());
} else {
// operator is not a sink! recurse in children
if (children.empty()) {
// source
state.SetPipelineSource(current, this);
} else {
if (children.size() != 1) {
throw InternalException("Operator not supported in BuildPipelines");
}
state.AddPipelineOperator(current, this);
children[0]->BuildPipelines(current, meta_pipeline);
}
}
}
在默认的BuildPipelines函数中,首先meta_pipeline可以通过GetState()得到 PipelineBuildState。可以通过state对象来设置Pipeline的Sink,Source或追加中间Operator。然后是三个分支逻辑:
-
如果当前Operator是IsSink(),则将自身作为当前Pipeline的Source,并通过CreateChildMetaPipeline创建一个新的MetaPipeline并递归执行Build(),并将当前Operator作为Pipeline Breaker开启新的 Pipeline.
-
如果当前算子是Source,则直接将自身作为当前Pipeline的Source.
-
如果当前算子是中间的无状态Operator,则通过state.AddPipelineOperator将自身追加到Pipeline末尾,最后按下一个算子递归执行BuildPipelines。
Reference
- Notes on Duckdb: Build Pipelines, https://zhuanlan.zhihu.com/p/609337363
- [DuckDB] Push-Based Execution Model, https://zhuanlan.zhihu.com/p/402355976
- Viktor Leis, Peter Boncz, Alfons Kemper, and Thomas Neumann. “Morsel-driven parallelism: a NUMA-aware query evaluation framework for the many-core age.” ACM International Conference on Management of Data (SIGMOD), pp. 743-754. 2014.
- Thomas Neumann. “Efficiently compiling efficient query plans for modern hardware.” VLDB Endowment 4, no. 9 (2011): 539-550.