Nvidia DCGM
During a recent project involving DCGM, I noted down some observations and have compiled them in this blog.
What are Tensor Cores? Why we need them on Nvidia GPUs?
Tensor cores are dedicated hardware units that exist alongside CUDA cores on the same GPU chip. Tensor Cores on NVIDIA GPUs are primarily designed for matrix multiply-accumulate (MMA) operations. They’re specialized processing units that can perform mixed-precision matrix operations much more efficiently than traditional CUDA cores. MMA is one of the foundational operations of modern AI applications, so it is super important to optimze and accerlate MMA operations.
Matrix multiply-accumulate (MMA) refers to a specialized computer operation that efficiently performs matrix multiplication followed by accumulation. The basic operation can be expressed as:
C = A × B + C
Where A, B, and C are matrices, and the result is accumulated into the existing matrix C.
Tensor Cores don’t support FP32?
FP64, FP32, FP16 represents double float, single float, and half float, respectively.
Tensor cores generally support FP16/TF32 and FP64, however, don’t support MMA operation in FP32 format, i.e., FP32 × FP32 -> FP32 for some reasons.
-
Tensor cores are built for maximum throughput, not maximum precision. Supporting FP32 would fundamentally conflict with this goal since FP32 operations require larger hardware units and are much slower but consume much more energy than FP16 that is widely used in modern neural networks.
-
Modern neural networks train fine with FP16/TF32, and HPC or scientific computing may require FP64, so there is no clear market segmentation.
-
For some scenarios where FP32 is definitely needed, Nvidia’s solution is TF32, which keeps FP32’s range but sacrifice FP32’s precision for emulating FP32. One way to think the magic behine FP32 is that both FP32 and TF32 are rulers the former can measure from 1 millimeter to 1000 kilometers with marking every 0.1 millimeter, the latter also measure from 1 millimeter to 1000 kilometers but with marking every 1 millimeter.
Thus, tensor cores usually support FP16, TF32, and FP64 in advanced GPU architecture such as Ampere.
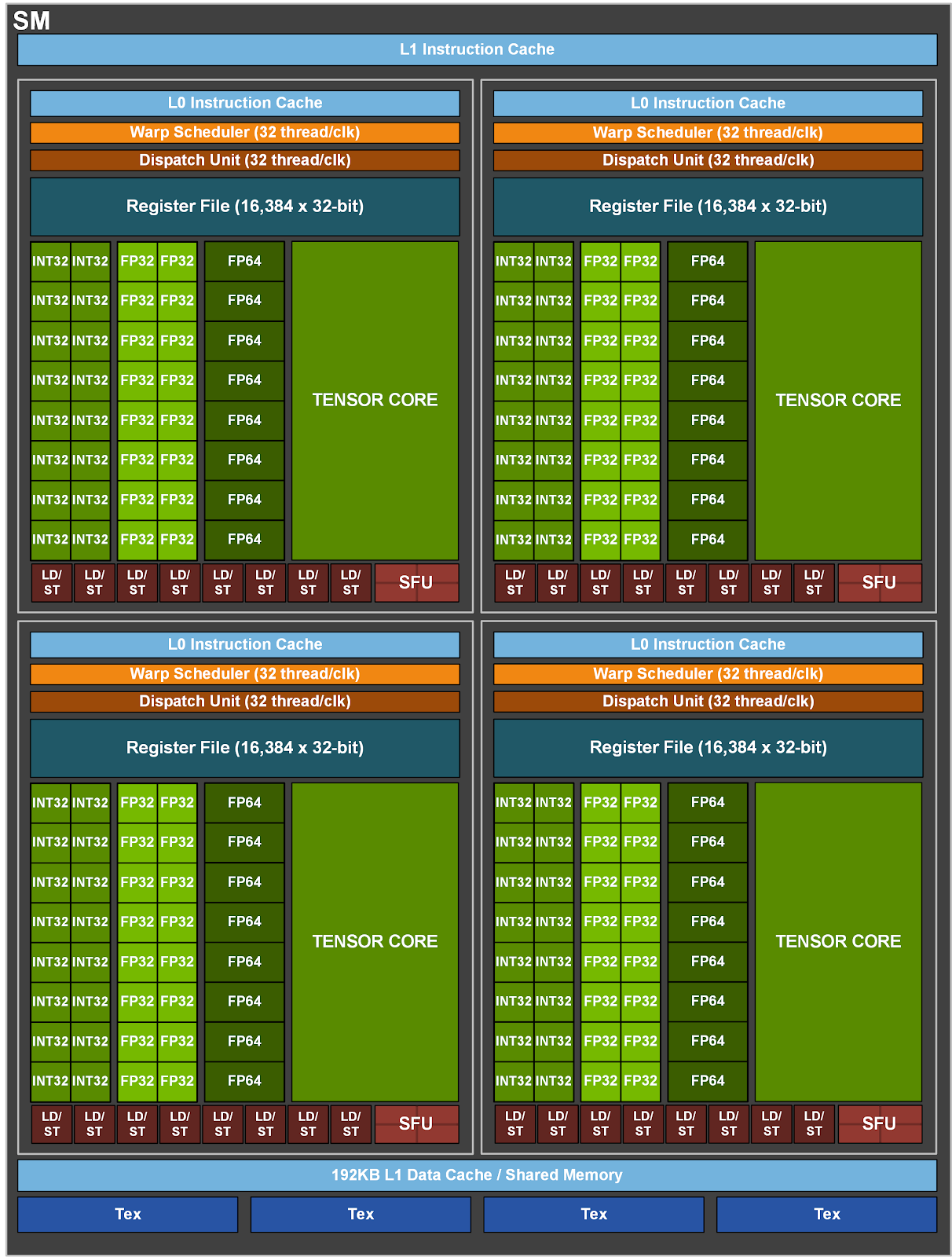
Are FP16, TF32, FP64, or Tensor computation are handled by dedicated hardware on GPU?
Modern GPUs do have dedicated hardware units for different precisions, though the extent varies by architecture. Taking the A100 GPU architecture, as shown in the following figure, it has dedeciate hardware unit for INT32, FP32, FP64, and Tensor. Also, FP16 usually can be handled by FP32, and TF32 are processed by Tensor Cores as well.
Gauge vs Counter in DCGM
A gauge is a metric that represents a single numerical value that can arbitrarily go up and down. It’s used for metrics that can increase and decrease, such as current memory usage, CPU utilization, or the number of active connections.
A counter is a cumulative metric that only increases in value or resets to zero. It’s used to measure values that continuously grow over time, such as the total number of requests processed or errors encountered.
Multiplexing of Profiling Counters
| The best or most efficient practice of collecting DCGM metrics is collect all the needed metrics togther at once. However, some metrics require multiple passes to be collected and therefore all metrics cannot be collected together. Due to hardware limitations on the GPUs, only certain groups of metrics can be read together. For example, SM Activity | SM Occupancy cannot be collected together with Tensor Utilization on V100 but can be done on T4. |
The command dcgmi profile -l -i 0 can show the metrics that can be collected together for a specific GPU. The metrcs that are in the same group–have the same group code can be collected together without additional multiplexing. For the metrics hat have the different grou codes, DCGM supports automatic multiplexing of metrics by statistically sampling the requested metrics and performing the groupings internally.
This may be transparent to users but may bring potential additional overhead.
Reference:
- The NVIDIA Data Center GPU Manager (DCGM), https://docs.nvidia.com/datacenter/dcgm/latest/user-guide